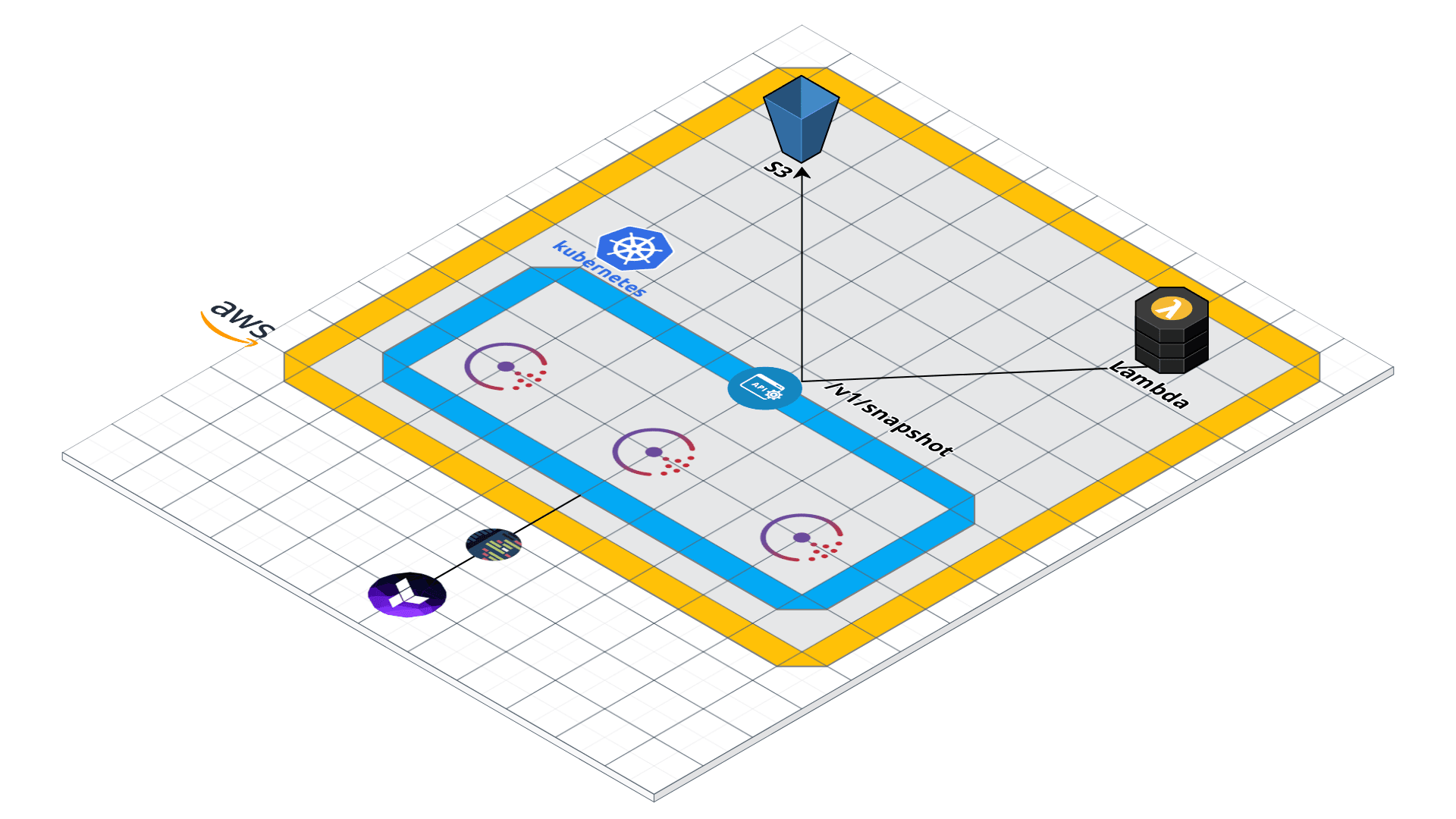
We recently had the need to backup a cluster deployed in
. Since the amount of cluster members may vary, there was no way to designate a snapshot manager in the cluster. We also found it more logical to keep the Consul pods as lean as possible.
We choose to delegate the Consul snapshot job to a serverless compute system.
The architecture
Introduction

- Node.js
- Java
- C#
- Go
- Python
This use case implements a Python code that makes an HTTP request to the Consul API and pipe the result to S3.
The idea is to have a code that is able to take the snapshot, store it into S3 and that is executed on a daily basis.
Backup.py
The backup.py file is actually the code that will be pushed to Lambda.
#!/usr/bin/env python
import os
import boto3
from botocore.vendored import requests
def GetSnapshot():
try:
snapshot = requests.get(
"https://consul.example.com/v1/snapshot",
headers={
"X-Consul-Token": "xxxxxx-xxxxxx-xxxxxxx-xxxxxxx"
}
)
except Exception, e:
print e
return snapshot.content
def SaveSnapshotToS3():
try:
s3 = boto3.resource('s3')
object = s3.Object(os.environ["BUCKET_NAME"], 'snapshot.tgz')
object.put(Body=str(GetSnapshot()))
except Exception, e:
print e
def lambda_handler(event, context):
SaveSnapshotToS3()
Terraform code
This snippet is used to create the needed AWS objects (IAM role, S3 bucket, Lambda function …).
provider "aws" {}
data "aws_iam_role" "consul_snapshot" {
name = "consul-snapshot"
}
data "archive_file" "function" {
type = "zip"
source_file = "${path.module}/backup.py"
output_path = "${path.module}/backup.zip"
}
The Lambda function code has to be wrapped in a zip archive to be accepted by Lambda.
resource "aws_s3_bucket" "consul_snapshot" {
bucket = "${var.cluster_name}-snapshot"
acl = "private"
tags {
Name = "${var.cluster_name}-snapshot"
}
}
The S3 bucket will host the snapshot file.
resource "aws_lambda_function" "consul_snapshot" {
filename = "backup.zip"
function_name = "${var.cluster_name}-snapshot"
role = "arn:aws:iam::246806011301:role/consul-snapshot"
handler = "backup.lambda_handler"
runtime = "python2.7"
source_code_hash = "${base64sha256(file("backup.zip"))}"
role = "${data.aws_iam_role.consul_snapshot.arn}"
environment {
variables = {
BUCKET_NAME = "${var.cluster_name}-esl-snapshot"
}
}
}
resource "aws_cloudwatch_event_rule" "consul_snapshot" {
name = "${var.cluster_name}-snapshot-daily"
schedule_expression = "cron(0 0 * * ? *)"
depends_on = [
"aws_lambda_function.consul_snapshot"
]
}
resource "aws_cloudwatch_event_target" "consul_snapshot" {
target_id = "${var.cluster_name}-snapshot-daily"
rule = "${aws_cloudwatch_event_rule.consul_snapshot.name}"
arn = "${aws_lambda_function.consul_snapshot.arn}"
}
resource "aws_lambda_permission" "consul_snapshot_daily" {
statement_id = "AllowExecutionFromCloudWatch"
action = "lambda:InvokeFunction"
function_name = "${aws_lambda_function.consul_snapshot.arn}"
principal = "events.amazonaws.com"
source_arn = "${aws_cloudwatch_event_rule.consul_snapshot.arn}"
}
Finally, above is the Lambda function definition, split in 4 Terraform resources :
- The Lambda function itself that designate which zip archive will be used as function code container.
- The Cloudwatch event rule that is here a cronjob definition (can be a
)
- The Cloudwatch event target which map the Lambda function and the Cloudwatch event rule.
- And finally the permission that allow the Cloudwatch event to trigger the Lambda function.
Result
After Terraformation, we obtain :


The first screenshot present the lambda function components. The second screenshot show the S3 object pushed to the bucket by the lambda function.
Conclusion
This little post demonstrate how to solve problems when it comes to find a way to execute backups on elastic cluster but also how to keep services clean by externalizing tasks scheduling on serverless compute.
It can be more efficient to choose a serverless solution for simple scheduling or small processing rather than pay for an underused instance that has to be managed.